

今回は購買・資材・調達部門でのデータ分析について紹介します。
こちらの記事ではこんな方にオススメです!
・データ分析に興味のある調達部の方
・調達部で働く中堅社員の方
昨今では、AI・機械学習などの分野が急激な成長を見せており、データを活用した業務改革が製造業でも注目されております。
製造業DXとしてマーケティング領域から製造品質まで幅広い領域でデータ活用は求められております。
しかし、製造業の設計部門や開発部門以外は文系出身者が多く、数値やITに苦手意識を持つ方も多いと思います。
調達部門もほとんどが文系出身者の為、データ分析と聞いて苦手意識を持たれる方も多いのではないでしょうか。
そこで今回は、そんな文系出身者でも明日から実施できるデータ分析を複数回の講座に分けてご紹介していきます!
第1回目の今回のポイントは下記になります。
・調達部門のデータ分析とは?
・データ分析に必要な準備内容
・調達部門におけるデータ分析の注意点
他にも、『調達バイヤーが必ず身に付けるべきスキル』についてはこちらの記事でご紹介しておりますので、是非併せてご覧ください!

調達部門のデータ分析とは?
調達部門で行うデータ分析とは主に価格の妥当性評価になります。
具体的には、サプライヤーからの回答価格が妥当なのかどうかを判断する際に用いられます。
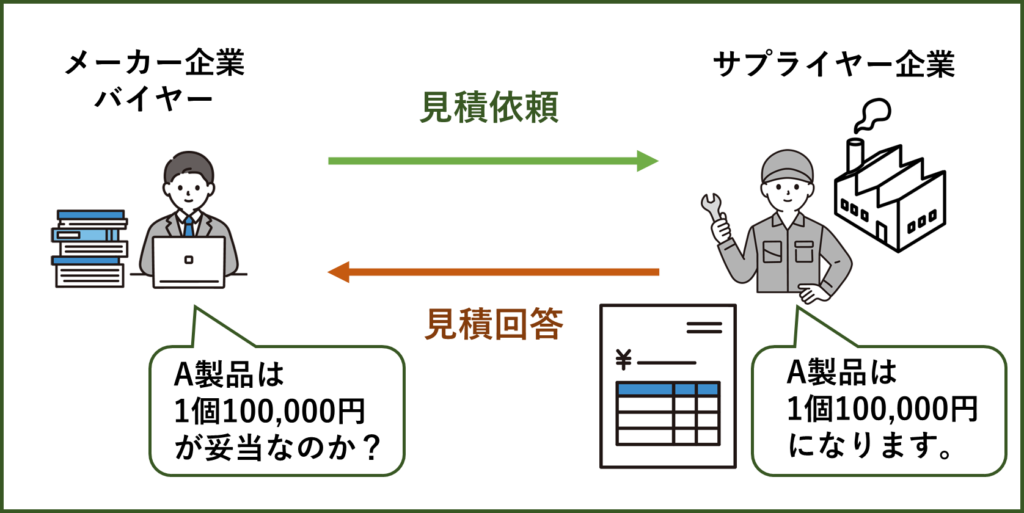
特に、新人バイヤーや担当品目が変わったばかりのバイヤーは、経験不足のため製品価格の妥当性を判断することは非常に難しいです。
そんな時にデータ分析が有効です。
ハイレベルのデータ分析ではAIや機械学習などを用いることが多いですが、データ分析とはもっと気軽に捉えても良いアプローチです。
数値の大小を比較するだけでもデータ分析と呼べますし、簡単な統計知識を学べば大半のデータ分析を理解することができます。
なので、データ分析は非常に簡単なアプローチであると捉えてください!
データ分析に必要な準備内容
それでは、具体的に調達部門でデータ分析を実施する場合、どのような準備が必要なのでしょうか?
今回はExcelを活用したデータ分析のケースを例に事前準備内容をご紹介します。
前提として、社内基幹システムなどのSQL操作とは切り離し、あくまでローカル環境で実施するレベルを想定しております。
早速ですが、データ分析の前段階として下記の5ステップを行いましょう!
STEP1:データ分析対象を決める
STEP2:データベースを準備する
STEP3:文字揺れやデータ成形を実施
STEP4:コストドライバーとなる変数を洗い出す
STEP5:記述統計量や相関行列の実施で変数を決定
STEP1 データ分析対象を決める
データ分析の対象を決める為の簡単な判断軸は、間接材・副資材以外を選ぶことです。
間接材や副資材はECサイトやオンライン販売が主流で、市場の競争原理により価格確認が容易です。
価格.COMを見れば分かるという感じです。
しかし、BtoBの場合は会社毎に仕様が異なる場合が多いです。
データ分析の対象はそのような会社毎に生産をする受注生産品になります。
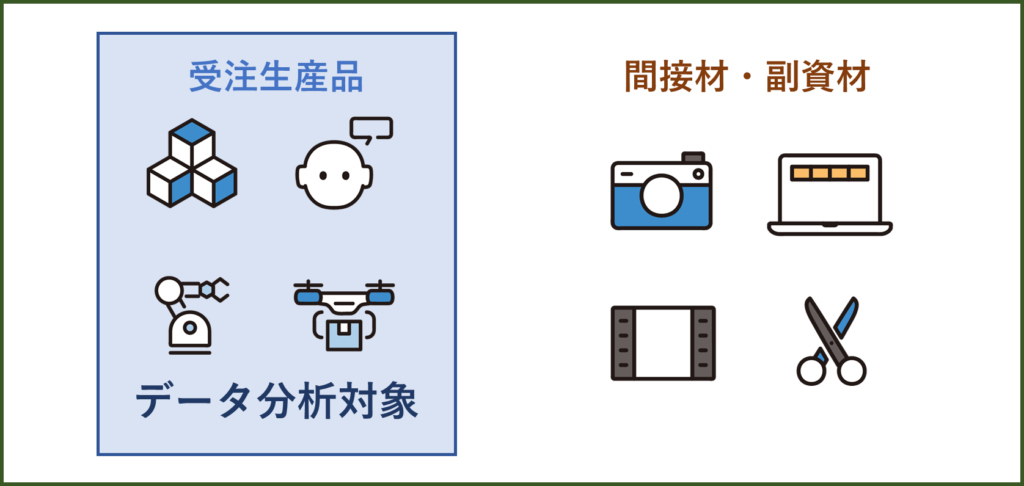
受注生産品の特徴は、
・類似品であるが、案件ごとに若干仕様が異なる
・過去実績やネットで価格を確認できない
このような特徴のある部品・製品はデータ分析対象にすると良いでしょう。
STEP2 データベースを準備する
次のステップはデータベースの準備です。
今回はExcelを使ったデータ分析を行いますので、Excelでデータベースを作成しましょう。
しかし、そう簡単にデータベースを作成できないため、8割のバイヤーはここで断念してしまいます。
もし基幹システムや購買システムでデータ蓄積がある場合は、データウェアハウスからcsv等で出力してもらいましょう。(ほとんどの企業でできていないです。)
まず準備するデータは、価格(単価)情報と仕様情報です。
下記のようなイメージでデータを準備しましょう。だいたいサンプル数は100くらいあると良いですね。
一旦、この段階では変数(仕様項目、列名)は多めに準備しておきましょう。
STEP3 表記ゆれ・欠損値のデータクレンジングを実施
一旦、データベースを準備したら表記ゆれの修正や欠損値補完などのデータクレンジングを行っていきます。
正直、この工程がかなり時間を使います。
分析自体は一瞬なのですが、その事前準備が非常に大変なのがデータ分析です。肝に銘じておきましょう。
表記ゆれ
表記ゆれとは、データベースの中で同じ意味の言葉が複数の表記になっている状態を指します。
例えば、「サーバー」、「サーバ」、「鯖」、「server」、「Server」、等のように、「サーバー」に対して複数の表記が混在している場合を指します。
これでは、全て別物として認識されてしまう為、すべてを「サーバー」に統一する処理が必要になります。
欠損値
欠損値とは、データベースの中で空欄になっているものです。
例えば、アンケートなどのデータを利用する場合、回答が無いものは欠損値となります。(下記では太枠)
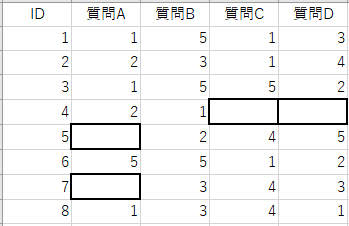
では、欠損値があるサンプルはどうすればよいでしょうか?
基本的に、平均値を代わりに入力するなどの対応が多いです。
また、入力値の最小値~最大値でランダムに複数回代入し、分析結果を平均する手法などもあります。
STEP4 コストドライバーとなる変数を洗い出す
次にコストドライバーとなる変数を洗い出します。
データベースの準備の際に、とにかく色々な変数を準備したと思いますが、ここからは『価格に影響する要因』に注目します。
その為、データベースの中からコストドライバーとなる変数を残します。
しかし、どうやってコストドライバーとなるかどうかを判断するのでしょうか?
ポイントは下記です。
・ベテラン社員や設計者などの知見をヒアリングする
・重回帰分析などで統計的に因果関係を確認する
まずはベテラン社員や設計者などにヒアリングしてみましょう!
STEP5 記述統計量や相関行列の実施で変数を決定
記述統計量、相関行列とは何ぞや?と思われたかと思いますが、データ分析をする上で事前に行う統計的な数値の確認です。
記述統計量
記述統計量とは、データ分布の特徴を要約する為に必要な指標のことです。
簡単に言うと、そのデータの特徴を捉えるための重要指標を集めた一覧です。
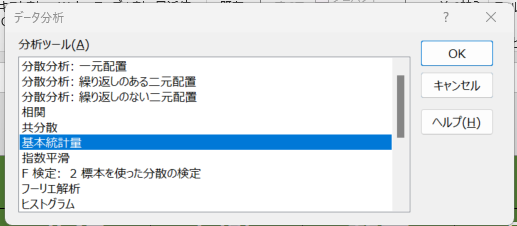
イメージは下記になります。
ある小学校の5教科のテスト結果を参考に見てみましょう。
右上のデータ分析のボタンを押します。(未表示の場合はオプションから表示させましょう。)
「基本統計量」を押して、「OK」を押します。
数値部分のみを範囲選択し、任意の出力情報を設定し、出力先を任意に設定したら「OK」を押します。
「OK」を押すと、下記のような記述統計量が任意の位置に表示されます。
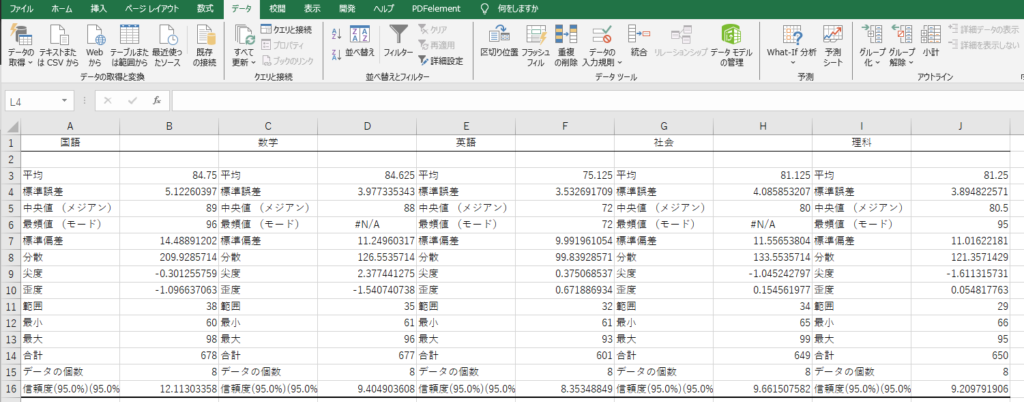
おなじみの平均値、標準偏差、最大最小値などが一覧でまとめられております。
分析前にデータ分布の特徴を掴みましょう!
相関行列
相関行列とは、分析に用いる変数間の相関を確認するマトリックスです。
同様に、小学校の5教科のテスト結果を参考に見てみましょう。
右上のデータ分析のボタンを押します。(未表示の場合はオプションから表示させましょう。)
「相関」を押して、「OK」を押します。
数値部分のみを範囲選択し、出力先を任意に設定し、「OK」を押します。
「OK」を押すと、下記のような相関行列が任意の位置に表示されます。
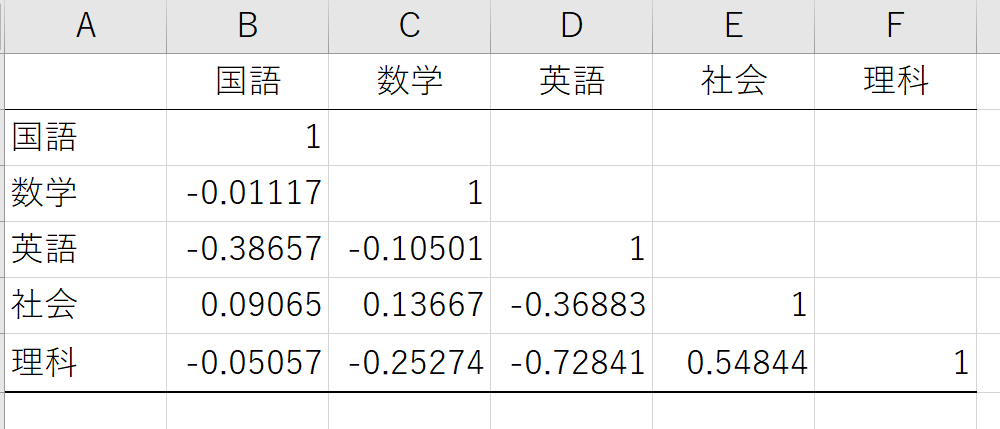
なぜ相関行列を実施するのかというと、変数間の相関が強い場合、「多重共線性」(マルチコリニアリティ:通称マルチコ)という解析結果が不安定な状態となります。
「多重共線性」を避けるため、おおむね相関係数が0.8~1.0などの変数はどちらか一方を変数から外します。
例えば、「価格」を分析する為の説明変数として「面積」と「体積」を両方変数に入れていると、似た要素の「面積」と「体積」は多重共線性になる可能性が高いので、より情報の少ない「面積」を変数から外すことを検討します。
調達部門におけるデータ分析の注意点
調達部門におけるデータ分析の注意点はいくつかあります。
・分析結果の「価格」が絶対とは限らない。
・取引先が分析結果の「価格」を認めてくれない。
・外部要因等の追加変数が出てくるリスクがある。
今回記載した注意点は一部ですが、実際にデータ分析した結果を活用する為には大きなハードルがあります。
なので、「分析することがゴールではなく、活用して〇〇する」というゴールも明確化して、意識しながら進めていきましょう!
まとめ
今回は購買・資材・調達部門でのデータ分析について紹介しました。
ポイントは下記3点でした。
・調達部門のデータ分析とは?
・データ分析に必要な準備内容
・調達部門におけるデータ分析の注意点
次回(その②)では実際にデータ分析を進めていきたいと思います。
この記事では有料級の情報を惜しみなくお伝えしていければと思います。
他にも、『購買・資材・調達DXが進まないワケ』についてこちらの記事でご紹介しておりますので、是非併せてご覧ください。

今回は以上です。
引き続きSetchan調達ブログを宜しくお願い致します!








コメント